UK Glamping Market Growth Fueled by Experiential Travel Preferences
Other |
2026-06-24 12:20:56

Upgrade to Pro
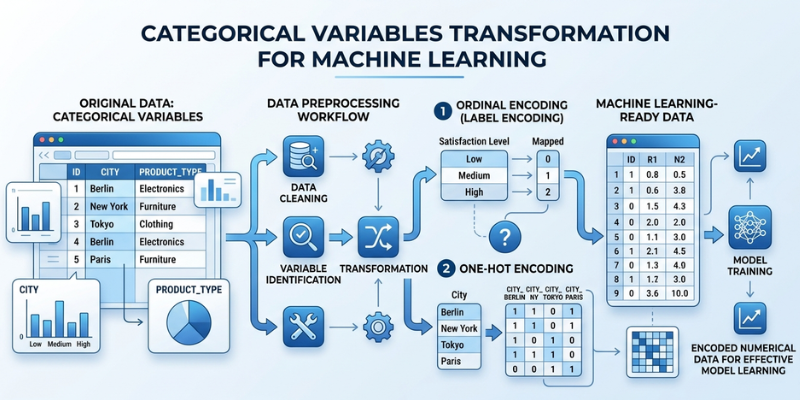
Categorical variables are an important part of many datasets. They represent information that can be grouped into categories rather than measured as numbers. Examples include gender, city, product type, customer segment, and payment method. Since machine learning algorithms work best with numerical data, categorical variables often need special handling before they can be used in analysis or modeling.
Understanding how to manage categorical data correctly can improve model performance and help generate more accurate insights. If you want to build stronger practical skills in this area, you can take a Data Science Course in Mumbai at FITA Academy and gain hands-on experience with real datasets.
Categorical variables contain values that represent labels or groups. Unlike numerical variables, these values do not describe measurable quantities. For example, colors such as red, blue, and green are categories rather than numbers.
There are generally two types of categorical variables. The first type is nominal data, where categories have no natural order. Examples include country names and product categories. The second type is ordinal data, where categories follow a meaningful order. Examples include customer satisfaction levels such as low, medium, and high.
Recognizing the type of categorical variable is important because different handling techniques may be required for different situations.
Most machine learning algorithms perform calculations using numbers. When categorical values are provided directly, the algorithm may not understand their meaning. As a result, predictions can become inaccurate or misleading.
Properly transforming categorical variables helps algorithms identify patterns more effectively. It also reduces the risk of introducing errors during model training. Choosing the right transformation method depends on the dataset, the number of categories, and the problem being solved.
One of the most widely used methods is label encoding. In this method, a distinct numerical value is given to each category. This technique is often suitable for ordinal variables because the categories already have a logical order.
Another popular method is one-hot encoding. This technique creates separate columns for each category and uses binary values to indicate whether a category is present. It is commonly used for nominal variables because it avoids creating a false sense of order between categories.
Frequency encoding is another useful approach. It replaces categories with their occurrence frequency in the dataset.
This approach may be beneficial when managing variables that have numerous distinct categories. As you continue learning these techniques, you may find it valuable to join a Data Science Course in Kolkata and practice applying different encoding methods to real-world business problems.
Handling categorical variables is not always straightforward. One common challenge is high cardinality, which occurs when a variable contains a large number of unique categories. Examples include customer IDs, product names, or postal codes.
High-cardinality variables can increase dataset complexity and create large numbers of features. In such situations, grouping rare categories or using alternative encoding methods can help simplify the data.
Another challenge is missing values. When category information is unavailable, it is important to decide whether to create a separate category for missing values or use another suitable strategy. The choice should align with the goals of the analysis.
Before applying any encoding technique, take time to understand the business context behind the data. A method that works well for one dataset may not be suitable for another.
It is also helpful to evaluate how different encoding approaches affect model performance. Testing multiple methods can reveal which option produces the most reliable results.
Maintaining clear documentation of data transformations is equally important. Good documentation makes projects easier to understand, reproduce, and improve over time.
Handling categorical variables effectively is a fundamental skill in data science. By understanding the nature of categorical data and selecting appropriate transformation techniques, you can prepare datasets for more accurate analysis and better predictive models. Consistent practice with real datasets will help you develop confidence and improve your ability to make informed decisions when working with categorical features. If you are ready to deepen your knowledge, consider a Data Science Course in Delhi and strengthen your expertise through structured learning and practical application.
Also check: The Bias-Variance Tradeoff Explained Simply



